深度学习笔记 (二) 在TensorFlow上训练一个多层卷积神经网络
上一篇笔记主要介绍了卷积神经网络相关的基础知识。在本篇笔记中,将参考TensorFlow官方文档使用mnist数据集,在TensorFlow上训练一个多层卷积神经网络。
下载并导入mnist数据集
首先,利用input_data.py来下载并导入mnist数据集。在这个过程中,数据集会被下载并存储到名为”MNIST_data”的目录中。
1 | import input_data |
其中mnist是一个轻量级的类,其中以Numpy数组的形式中存储着训练集、验证集、测试集。
进入一个交互式的TensorFlow会话
TensorFlow实际上对应的是一个C++后端,TensorFlow使用会话(Session)与后端连接。通常,我们都会先创建一个图,然后再在会话(Session)中启动它。而InteractiveSession给了我们一个交互式会话的机会,使得我们可以在运行图(Graph)的时候再插入计算图,否则就要在启动会话之前构建整个计算图。使用InteractiveSession会使得我们的工作更加便利,所以大部分情况下,尤其是在交互环境下,我们都会选择InteractiveSession。
1 | import tensorflow as tf |
利用占位符处理输入数据
关于占位符的概念,官方给出的解释是“不是特定的值,而是可以在TensorFlow运行某一计算时根据该占位符输入具体的值”。这里也比较容易理解。
1 | x = tf.placeholder("float", shape=[None, 784]) |
x代表的是输入图片的浮点数张量,因此定义dtype为float。其中,shape的None代表了没有指定张量的shape,可以feed任何shape的张量,在这里指batch的大小未定。一张mnist图像的大小是28*28,784是一张展平的mnist图像的维度,即28*28=784。
1 | y_ = tf.placeholder("float", shape=[None, 10]) |
由于mnist数据集是手写数字的数据集,所以分的类别也只有10类,分别代表了0~9十个数字。
权重与偏置项初始化
在对权重初始化的过程中,我们加入少量的噪声来打破对称性与避免梯度消失,在这里我们设定权重的标准差为0.1。 由于我们使用的激活函数是ReLU,而ReLU的定义是$$y=
\begin{cases}
0& (x\ge0)\\
x& (x<0)
\end{cases}$$
ReLU对应的图像是下图左边的函数图像。
但是我们可以注意到,ReLU在$x<0$的部分是硬饱和的,所以随着训练推进,部分输入可能会落到硬饱和区,导致权重无法更新,出现“神经元死亡”。虽然在之后的研究中,有人提出了PReLU和ELU等新的激活函数来改进,但我们在这里的训练,还是应该用一个较小的正数来初始化偏置项,避免神经元节点输出恒为0的问题。
1 | #初始化权重 |
卷积与池化
在这里,我们使用步长为1、相同填充(padding=’SAME’)的办法进行卷积,关于相同填充和有效填充的区别在上一篇笔记讲得比较清楚了,在这里就不赘述了。与此同时,使用2x2的网格以max pooling的方法池化。
1 | # 卷积过程 |
第一层卷积
(1 #28x28->32 #28x28)
首先在每个5x5网格中,提取出32张特征图。其中weight_variable中前两维是指网格的大小,第三维的1是指输入通道数目,第四维的32是指输出通道数目(也可以理解为使用的卷积核个数、得到的特征图张数)。每个输出通道都有一个偏置项,因此偏置项个数为32。
1 | w_conv1 = weight_variable([5, 5, 1, 32]) |
为了使之能用于计算,我们使用reshape将其转换为四维的tensor,其中第一维的-1是指我们可以先不指定,第二三维是指图像的大小,第四维对应颜色通道数目,灰度图对应1,rgb图对应3.
1 | x_image = tf.reshape(x, [-1, 28, 28, 1]) |
而后,我们利用ReLU激活函数,对其进行第一次卷积。
1 | h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) |
第一次池化
(32 #28x28->32 #14x14)
比较容易理解,使用2x2的网格以max pooling的方法池化。
1 | h_pool1 = max_pool_2x2(h_conv1) |
第二层卷积与第二次池化
(32 #14x14->64 #14x14->64 #7x7)
与第一层卷积、第一次池化类似的过程。
1 | w_conv2 = weight_variable([5, 5, 32, 64]) |
密集连接层
此时,图片是7x7的大小。我们在这里加入一个有1024个神经元的全连接层。之后把刚才池化后输出的张量reshape成一个一维向量,再将其与权重相乘,加上偏置项,再通过一个ReLU激活函数。
1 | w_fc1=weight_variable([7*7*64,1024]) |
Dropout
1 | keep_prob=tf.placeholder("float") |
这是一个比较新的也非常好用的防止过拟合的方法,想出这个方法的人基本属于非常crazy的存在。在Udacity-Deep Learning的课程中有提到这个方法——完全随机选取经过神经网络流一半的数据来训练,在每次训练过程中用0来替代被丢掉的激活值,其它激活值合理缩放。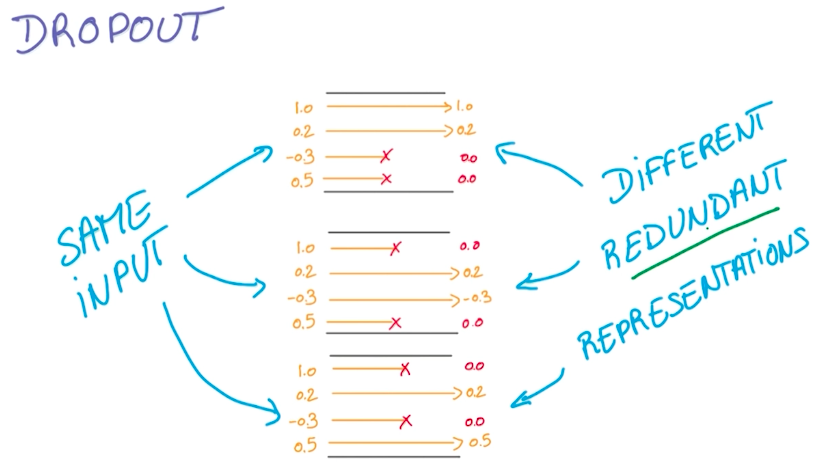
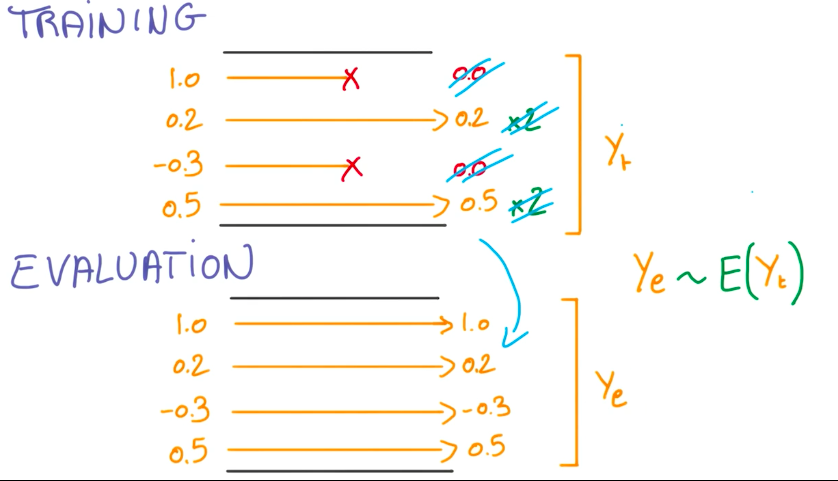
类别预测与输出
应用了简单的softmax,输出。
1 | w_fc2=weight_variable([1024,10]) |
模型的评价
1 | #计算交叉熵的代价函数 |
本文代码与部分内容来源或参考自:
TensorFlow官方文档
深度学习中的激活函数导引
Udacity-Deep Learning